Simon Willison, one of the more authoritative independent voices in the LLM space right now, published a good theory on what may have happened with Apple’s delay of Apple Intelligence’s Siri personalization features:
I have a hunch that this delay might relate to security.
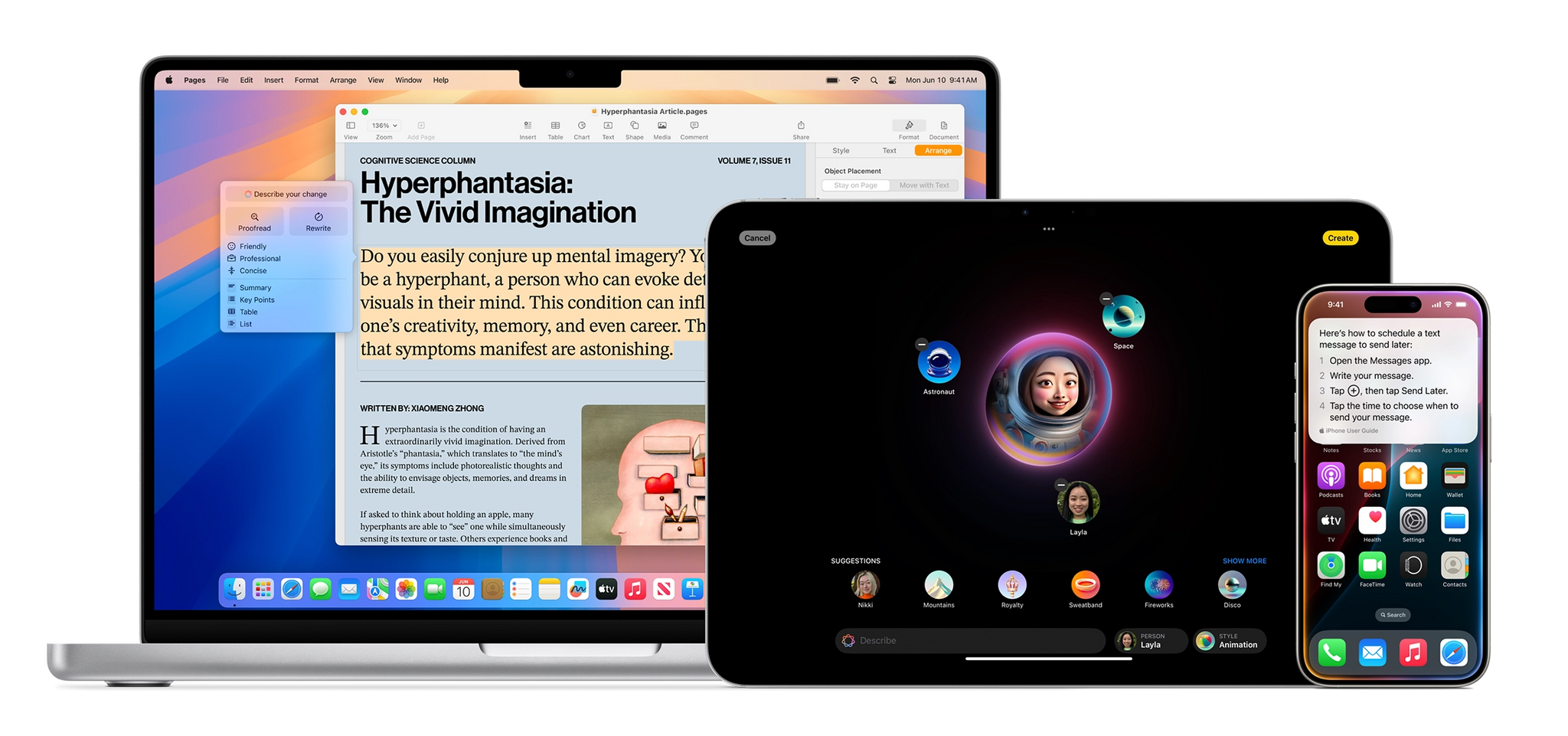
These new Apple Intelligence features involve Siri responding to requests to access information in applications and then perform actions on the user’s behalf.
This is the worst possible combination for prompt injection attacks! Any time an LLM-based system has access to private data, tools it can call and potentially malicious instructions (like emails and text messages from untrusted strangers) there’s a risk that an attacker might subvert those tools and use them to damage or exfiltration a user’s data.
Willison has been writing about prompt injection attacks since 2023. We know that Mail’s AI summaries were (at least initially?) sort of susceptible to prompt injections (using hidden HTML elements), as were Writing Tools during the beta period. It’s scary to imagine what would happen with a well-crafted prompt injection when the attack’s surface area becomes the entire assistant directly plugged into your favorite apps with your data. But then again, one has to wonder why these features were demoed at all at Apple’s biggest software event last year and if those previews – absent a real, in-person event – were actually animated prototypes.
On this note, I disagree with Jason Snell’s idea that previewing Apple Intelligence last year was a good move no matter what. Are we sure that “nobody is looking” at Apple’s position in the AI space right now and that Siri isn’t continuing down its path of damaging Apple’s software reputation, like MobileMe did? As a reminder, the iPhone 16 lineup was advertised as “built for Apple Intelligence” in commercials, interviews, and Apple’s website.
If the company’s executives are so certain that the 2024 marketing blitz worked, why are they pulling Apple Intelligence ads from YouTube when “nobody is looking”?
On another security note: knowing Apple’s penchant for user permission prompts (Shortcuts and macOS are the worst offenders), I wouldn’t be surprised if the company tried to mitigate Siri’s potential hallucinations and/or the risk of prompt injections with permission dialogs everywhere, and later realized the experience was terrible. Remember: Apple announced an App Intents-driven system with assistant schemas that included actions for your web browser, file manager, camera, and more. Getting any of those actions wrong (think: worse than not picking your mom up at the airport, but actually deleting some of your documents) could have pretty disastrous consequences.
Regardless of what happened, here’s the kicker: according to Mark Gurman, “some within Apple’s AI division” believe that the delayed Apple Intelligence features may be scrapped altogether and replaced by a new system rebuilt from scratch. From his story, pay close attention to this paragraph:
There are also concerns internally that fixing Siri will require having more powerful AI models run on Apple’s devices. That could strain the hardware, meaning Apple either has to reduce its set of features or make the models run more slowly on current or older devices. It would also require upping the hardware capabilities of future products to make the features run at full strength.
Inference costs may have gone down over the past 12 months and context windows may have gotten bigger, but I’m guessing there’s only so much you can do locally with 8 GB of RAM when you have to draw on the user’s personal context across (potentially) dozens of different apps, and then have conversations with the user about those results. It’ll be interesting to watch what Apple does here within the next 1-2 years: more RAM for the same price on iPhones, even more tasks handed off to Private Cloud Compute, or a combination of both?
We’ll see how this will play out at WWDC 2025 and beyond. I continue to think that Apple and Google have the most exciting takes on AI in terms of applying the technology to user’s phones and apps they use everyday. The only difference is that one company’s announcements were theoretical, and the other’s are shipping today. It seems clear now that Apple got caught off guard by LLMs while they were going down the Vision Pro path, and I’ll be curious to see how their marketing strategy will play out in the coming months.