I’ve already expressed my preference for archiving webpages as PDFs rather than simple “bookmarks” on an online service. When I come across a webpage that I know I want to keep for future reference, I like to generate a clean-looking PDF file with selectable text that I can rely on for years to come.
Lately, I have become obsessed with turning longer articles I find on the Internet also into PDFs for long-term archival. For as much as I like Instapaper, I can’t be sure that the service will be around in the next decades, and I don’t want my archive of longform and quality content to be lost in the cloud. So I have come up with a way to combine Instapaper with the benefit of PDFs, Dropbox, and automation to generate documents off any link or webpage, from any device, within seconds.
Yesterday I put together an iOS and OS X workflow to generate PDFs remotely on my Mac, starting from a simple bookmarklet on iOS. On an iPhone or iPad, I can simply hit a button in Safari, and wait for Pythonista to turn a webpage (that’s already been passed through Instapaper’s text bookmarklet) into an .html file in my Dropbox, which is then converted to PDF and added to Evernote. It sounds complex, but in actual practice I can go from a Safari webpage on iOS to a PDF in the Evernote app in around 30 seconds. Hopefully you’ll find this quick solution useful; feel free to modify it and/or send suggestions.
The script relies on Pythonista, which generates the actual .html file that is uploaded to Dropbox; Hazel and PDFpen, which monitor Dropbox and OCR the PDF on my remote Mac; and, last, Evernote, which creates a new note containing the file as PDF. I’ve already explained why I like using the Instapaper parser for PDF generation, and the underlying structure of the Pythonista script is based on the scripts I use with the app.
First, when I’m in Safari and I find a webpage that I want to archive, I hit the following bookmarklet in my Bookmarks Bar:
javascript:window.location='pythonista://MakePDF?action=run&argv='+encodeURIComponent(document.title)+'&argv='+encodeURIComponent(document.location.href);
The bookmarklet simply grabs a webpage’s name and URL as two separate parameters, which are sent to Pythonista using argv.
The script itself is fairly straightforward and inspired by Gabe Weatherhead’s use of urllib2.urlopen to get the text of a URL passed through the Instapaper bookmarklet. Like my previous scripts, the script checks if the number of arguments sent is less than two; in that case, it assumes I haven’t forwarded a webpage name and URL via bookmarklet, and proceeds to grab them using a link in the clipboard (Lines 18–24).
import clipboard import urllib2 import console from dropboxlogin import get_client dropbox_client = get_client() import keychain import time import webbrowser import sys import webbrowser import urllib import bs4 numArgs = len(sys.argv) console.clear() if numArgs
Line 33 composes a base URL for Instapaper’s parser, to which we’ll append the actual URL we want to turn into a PDF (as usual, strictly for personal use). Lines 39–43 request the URL, its contents (the HTML generated by Instapaper’s parser) and encode everything in UTF–8. Line 48 puts the HTML contents inside an .html file in my Dropbox using the method outlined in my original Pythonista review. At this point, the .html file is off to my Mac mini, which will process it. Line 54 waits 15 seconds (the time it usually takes my mini to finish conversion and OCR), and the last line of the script simply launches Evernote, which will have my PDF ready for further reading or organization.
On the Mac’s side, I rely on Hazel and PDFpen. I have started incorporating PDFpen in my paperless workflow recently, and I bought a Personal license last night because I absolutely love the software and the company behind it.
Yesterday, I noticed my previous solution to generate PDFs off .html files, wkpdf, wasn’t working properly on Mountain Lion. It always errors out in the shell on both 10.8 and 10.8 Server when I pass an .html file to it. Fortunately, per @themodernscientist recommendation I installed wkhtmltopdf, which is slightly slower than wkpdf but has a bunch of options to truly customize the look of your final PDF. You can read more about wkhtmltopdf here and here (I installed the “app” version and simply moved the executable using the Terminal command mentioned here). Specifically, I like how wkhtmltopdf lets you set a specific encoding and put a --no-background flag to strip an .html file off its background color.
The first Hazel rule monitors a folder for .html files, runs a shell script, and than trashes the original files.
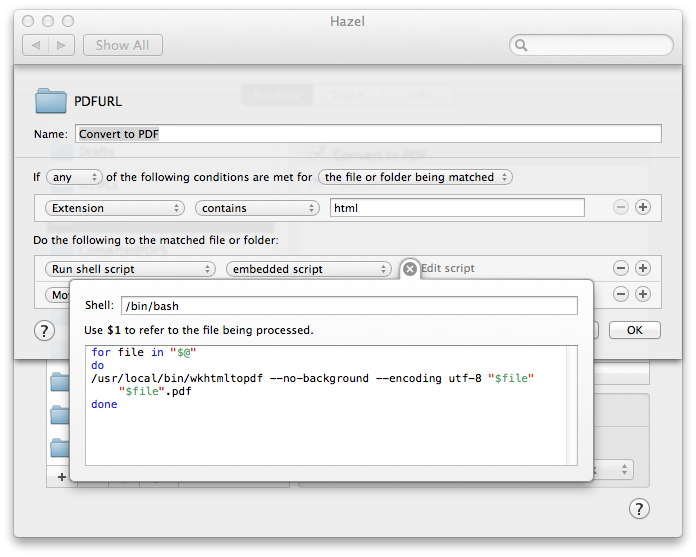
for file in "$@" do /usr/local/bin/wkhtmltopdf --no-background --encoding utf-8 "$file" "$file".pdf done
The second rule in the same folder uses AppleScript and PDFpen to apply OCR on the newly generated PDF file. As @themodernscientist points out there is a way to fix selectable text in wkhtmltopdf, but I like PDFpen’s OCR anyway, so I decided to use it instead. I found the original script on DocumentSnap’s website; I like it because it simply opens PDFpen, performs the OCR, and then closes the document automatically, saving it.
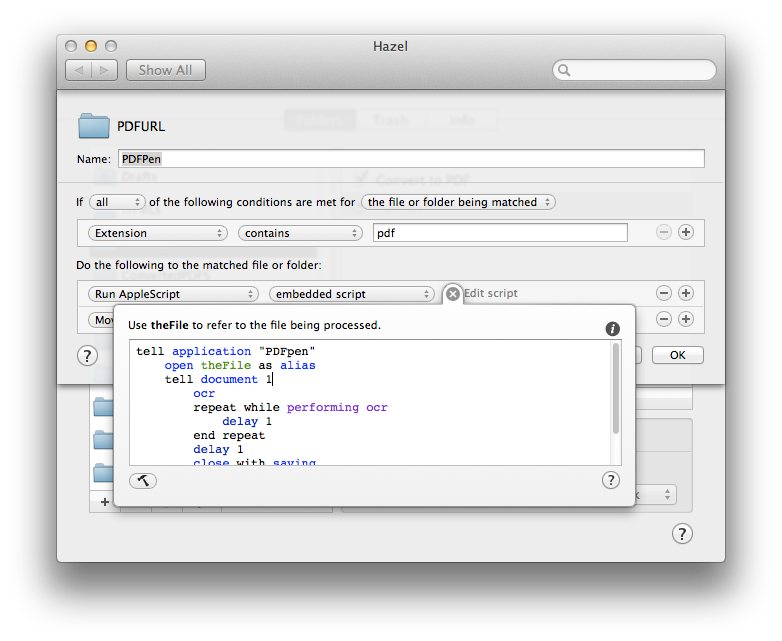
tell application "PDFpen" open theFile as alias tell document 1 ocr repeat while performing ocr delay 1 end repeat delay 1 close with saving end tell end tell
Once OCR’d, Hazel moves the document in a ConvertedPDFs folder that, upon receiving a new file, runs an AppleScript to add it to Evernote. This is the same script I use for my paperless workflow, and it’s based on my previous article about sending Mail messages to Evernote.
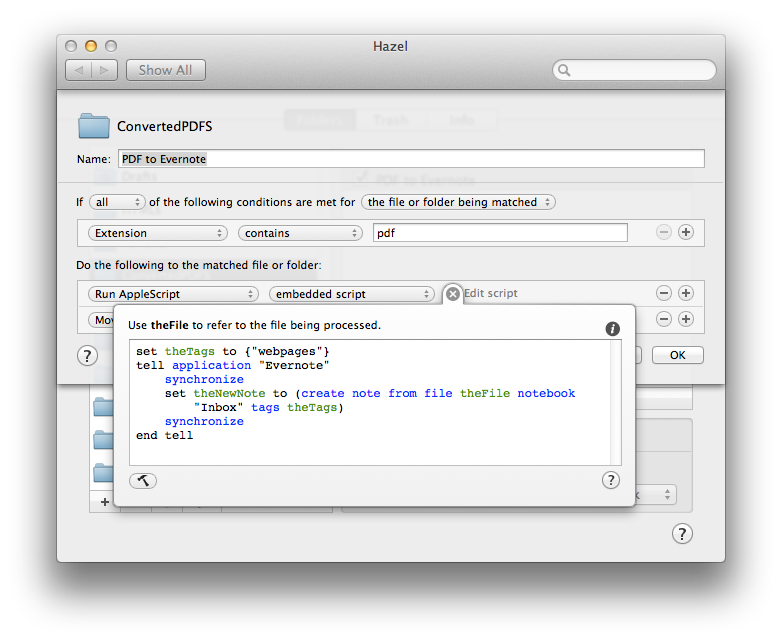
set theTags to {"webpages"} tell application "Evernote" synchronize set theNewNote to (create note from file theFile notebook "Inbox" tags theTags) synchronize end tell
And that’s it. While my iOS device is waiting with a “Converting to PDF…” message, my Mac takes care of transforming the .html file, putting a nice white background on the already-nice Instapaper-parsed text, applying OCR to the PDF, and moving it to Evernote. It takes seconds, it happens remotely and automatically, and I just need to wait for the finished document to end up in Evernote, which synchronizes immediately.
The use of the last line in Pythonista is debatable. In a first version of the script, I used webbrowser.open on an iCab-powered URL scheme to open a PDF moved to my Dropbox Public folder because I could simply “guess” the URL it would have at the end of the process. If you’re interested in such a worklfow, use something like this at the end of the script:
If you have suggestions or ideas for improvement, feel free to get in touch.
Update: Thanks to wkpdf developer Christian Plessl, here’s a simple fix to run wkpdf on .html files on Mountain Lion: simply add a --ignore-http-errors to the conversion command and wkpdf will suppress errors while still generating the PDF. In Hazel, add the following:
for file in "$@" do wkpdf --source "$file" --output "$file".pdf --ignore-http-errors done
As expected, wkpdf takes considerably less time than wkhtmltopdf and works nicely with Instapaper-parsed files, using a white background.